Ten years ago, computer scientists would contact our Center and ask if we could give them thousands of examples of cyberbullying content – which they wanted to comb through to look for trends and patterns in how harm was inflicted. Nowadays, they don’t ask for data because it’s widely available for them to web scrape from publicly available social media posts in the quantity they need (e.g., there are approximately 500 million tweets on Twitter every day). Along with the decreased cost of inexpensive hardware like (almost) unlimited storage space on hard drives and computing multiprocessors that can crunch and mine data at breakneck speeds, this has allowed the field to make some pretty cool technological breakthroughs to reduce online abuse. And I have to say, I’m pretty stoked about their potential.
Generally speaking, the overarching goal is to use artificial intelligence at a certain level (the device, the app, or ideally the cloud) to preempt victimization by:
- identifying (and blocking, banning, or quarantining) the most problematic users and accounts, or
- immediately collapsing or deleting content that algorithms predictively flag and label as abusive, or
- otherwise controlling the posting, sharing, or sending or messages that violate appropriate standards of behavior online.
I thought it would be valuable for our readers if I spent a bit of time defining some relevant terms, and then provide a real-world example that uses most/all of them. I think it’s easy for educators and many other youth professionals to simply gloss over this sort of stuff, but this is the future of combatting online abuse – not solely, but in conjunction with many other efforts. We have moved far beyond simple keyword or phrase blocking through black lists and filters (which school professionals are familiar with), and that is a great thing. I want everyone to understand this new direction on at least a basic level, and see its promise.
Important Terms
Algorithm – This is a list or set of rules that a computer will follow to accomplish some task or procedure via its calculations.
Machine Learning – This means that we use algorithms to get computer systems to go through content (images, text, whatever) and identify various trends and patterns across all of those data, based on what we have told them to look for (e.g., training it on labeled data – content that a human has already manually classified in some way – toxic or not toxic, abusive or not abusive). This can actually be done on unlabeled data as well, via what is called unsupervised learning – where the algorithm(s) tries to cluster the data into groups on its own).
Deep Learning – Basically, this is a subset of machine learning, but after we get the system to identify trends and patterns across data by analyzing content, we ask it to constantly improve its probability of accurately classifying that content by continually training itself on new data that it receives.
Neural Network – This is a logical set of algorithms that each operate on a layer and which iteratively takes some data (images, text, whatever) you feed it, and then performs some sort of task on it to aid in classifying it before passing it onto the next layer of neurons within that network. Typically, the more layers, the more is learned about each piece of content and the more accurately it can detect patterns and make accurate classifications.
Artificial intelligence (AI) – This is the field of computer science in which machine learning and deep learning are housed. It simply refers to devices or systems demonstrating intelligence and cognition previously associated with living beings.
Natural language processing (NLP) – This involves using machines to take human language in text or audio format – with all of its subtleties and nuances involving context, turn of phrase, colloquialisms, and tone – and deciphering what is meant, ideally with the accuracy that humans have in understanding expressed words and phrases.
Sentiment analysis – This involves using NLP to identify and parse out emotions (affect) and other subjective notions within expressed words or phrases. Within this, there is sentiment polarity (where a piece of content can be classified as positive, negative, or neutral in its emotion or tone) and a sentiment score (a numeric rating given to a piece of content on a continuum between two extreme values).
How Machine Learning Can Help Classify Online Abuse: An Example
Let’s consider some content that someone might post.
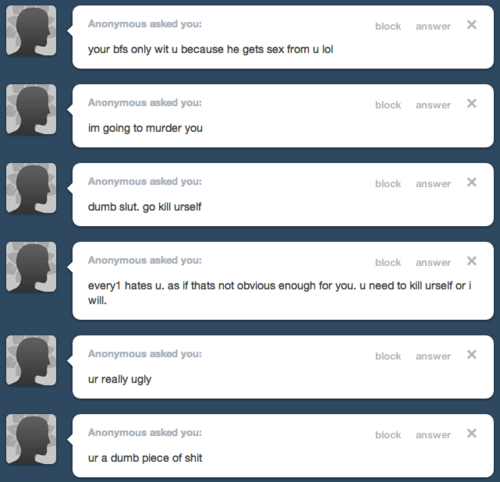
A programmer can take these posts (along with millions of other posts, good and bad) and use artificial intelligence within a machine learning framework – specifically deep learning to make determinations about them. She might first write multiple algorithms to do specific tasks. Together and collectively, those would form a neural network of layers, each with its own automated job to do.
- The first layer would take all of the texts by each user over the time frame of collected data, and extract curse words or hateful words which have previously been listed out by the programmer as abusive in nature (e.g, “slut,” “shit,” “ugly,” “hates”) .
- The second layer would count them up and divide them by the number of words in the text message where it appears, which may signal severity of the hatred involved.
- The third layer would count how many letters were in CAPS, which may signal how angry or incensed the poster was.
- The fourth layer would count how many posts with hateful words have second-person pronouns (“ur,” “you,” “you’re,” “u,” etc.), indicating that those words are lobbed at someone directly.
- The fifth layer would check to see whether this poster has had content flagged as abusive previously, and since past behavior is the best predictor of future behavior, it may signal that other posts by the same author are more likely to be abusive.
- The sixth layer would examine punctuation and special symbols to see if they give insight on tone, based on principles of natural language processing.
- The seventh layer would evaluate overall spelling and grammar to assess how hastily, spontaneously, and/or emotionally the post was written.
- The eighth layer would check to see if there is an attached image or video, and whether that image or video (based on its individual and unique digital fingerprint or “hash”) has been classified as abusive or toxic before.
Programmatically, the work of each of these layers across the posts in the screenshot above – and millions of others, abusive and not abusive – would be accumulated, appropriately weighed, and collectively used to gain artificial intelligence in understanding what posts are most likely to be toxic. Then, an algorithm can perform sentiment analysis to make a determination of whether the next post is or is not toxic (sentiment polarity), and consequently whether it should be flagged, blocked, or deleted by a human moderator (whose decision-making is simplified through this system). This can then happen on every new post created by a user, automatically and on-the-fly.
There are more layers to consider and evaluate (frequency of third-party reports on the post, use of emoticons, and how old the posting account is (as new accounts are often created to specifically troll and harass). I also know my example is not perfect, but hopefully you get the gist. As knowledge and technology in this area continues to develop, we will be increasingly able to identify what is abusive versus what is not.

How Machine Learning is Currently Being Used by Social Media Platforms
Major social media companies are currently using machine learning technology to help them match ads to users that will be of highest interest to them. In addition, it is helping to identify violent extremism and fake news. More importantly (to me), they are using machine learning to create and maintain inclusive, thriving environments for users, and are continually improving their algorithms based on the mountains of data they analyze. They are also using it to identify those who are portraying suicidal tendencies, evidence of self-harming behaviors, depression, or other mental health problems – issues we also care deeply about.
We really want to get to a point where technology can detect with a solid level of accuracy what a human moderator would flag as abusive or problematic. The main objective is to get in front of potentially major situations before they go viral. Or before someone makes a choice they cannot undo.
Combating Online Abuse via Algorithms is Tough
This stuff is really, really hard to do well. Really. I am sure you can think of many complicating factors:
- Some abuse is patently clear and explicit, while other forms are subtle, implicit, and carefully and intentionally crafted to slip past generic filters/blocks.
- Sometimes characters in hateful words are replaced with symbols to avoid automatic detection.
- Some posted content may not contain any problematic words but still might be incredibly offensive.
- Some content might contain historically offensive or abusive words, but is shared in jest or to make a point.
- Acronyms and Internet slang are changing constantly.
- Sometimes hate phrases are quoted within a non-hateful post, which could be unfairly and inaccurately censored or flagged.
Finally, it’s tremendously difficult to evaluate context, sarcasm, wit, and socioemotional cues in electronic communications. Just think about spam blocking technologies – they have come a long way, but you still get some junk in your inbox every couple of weeks (and some legitimate messages still get filtered out, unfortunately). Let’s be patient with them as they refine their use of this technology to better serve communities.
Here at the Cyberbullying Research Center, we are all about combatting online abuse in the best ways possible, and this is one of the next big frontiers. We have to keep coming up with both social and technological solutions to bear the most fruit, especially if they work in tandem. Each is valuable on their own, but together they are multiplicatively so. We will keep discussing this in the weeks and months ahead.

Above: Google’s Perspective API
Image sources:
https://specials-images.forbesimg.com/imageserve/524844346/960×0.jpg?fit=scale
https://www.sott.net/image/s19/380111/full/438753_how_to_be_a_jerk_in_int.jpg
https://venturebeat.com/2017/02/23/google-harnesses-machine-learning-to-help-publishers-thwart-abusive-comments-online/
The post How Machine Learning Can Help Us Combat Online Abuse: A Primer appeared first on Cyberbullying Research Center.